


TP 2
Wissensmanagement und Biomarkeridentifizierung
Die medizinische Forschung baut derzeit darauf, dass mehr und mehr Daten auch zu einem besseren Verständnis von Krankheiten und schließlich deren Heilung führen. Reine Daten müssen aber erst in einen Zusammenhang gebracht werden, ehe daraus Einsicht und Handlungen erwachsen können. So bleibt der Datenpunkt "rot" völlig unverständlich, solange der Zusammenhang "Ampel" nicht bekannt ist. Und auch dann müssen wir erst mühevoll lernen, dass eine rote Ampel "stehen bleiben" bedeutet. Mit Hilfe der Biomax BioXM(TM) Wissensmanagementsoftware wird in SYS-Stomach das bereits bekannt Wissen zu Magenkrebs gesammelt, mit den experimentellen Messungen der Magenkrebszellen integriert und in einer Form aufbereitet, die es ermöglicht daraus mathematische Krankheitsmodelle abzuleiten. Eine der Herausforderungen dabei ist, dass biomedizinsches Wissen weder einheitlich beschrieben noch an einer gemeinsamen Stelle abgelegt wird. So existieren derzeit neben 21 Millionen Veröffentlichungen über 1.500 spezialisierte Datenbanken, in denen Teile relevanten Wissens abgelegt wurden.
Zur Integration von Informationen aus diesen verschiedenen Quellen, muss nach geeigneten Schlüsselkategorien wie „Gen“, „Medikament“ oder “Mensch“ gesucht werden, an denen sich die verschiedenen Zusammenhänge wie „Mutation (in Gen) verursacht Krebs (Krankheit - Mensch)“ festmachen lassen. Durch diese semantische
Abbildung verschiedener Informationen entsteht ein immenses Wissensnetzwerk, das sich dann für die weitere Analyse nutzen lässt.
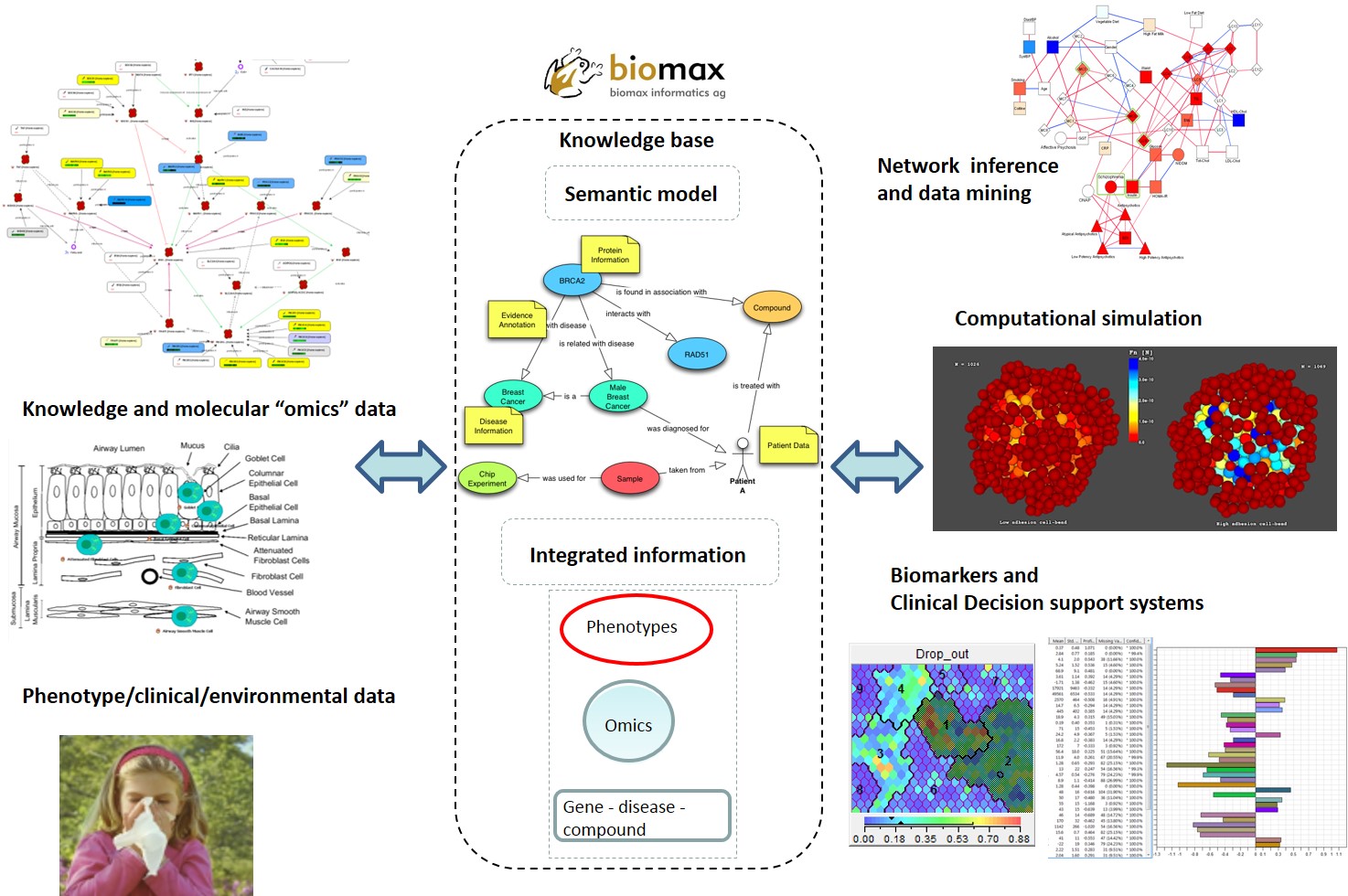
Ein Teil dieser Analyse beruht auf Maschinenlernverfahren, die große Datenmengen nach auffälligen Mustern durchsucht. Die Viscovery(R) Data Mining Suite verwendet dazu sogenannte "Self organising maps" die das Prinzip der Neuronalen Netzwerke anwenden. Wie in unserm Gehirn, das aus der Geräuschkulisse eines Festes den eigenen Namen heraushört, werden die Daten dabei nach Ähnlichkeit geordnet und dann nach Gruppen ("Cluster") aufgeteilt. Werden diese Gruppen nach Kategorien wie "gesund" und "krank" unterteilt kann man daraus mit statistischen Methoden diejenigen Parameter filtern, mit denen sich später eine Vorhersage ermöglichen lässt. Um auf das Ampelbeispiel zurückzukommen wäre das dann die Farbe des Ampellichtes aber nicht die Ampelhöhe.
Keywords: Wissensmanagement, Maschinenlernen, Semantische Abbildung, Netzwerkanalyse