


TP 10
Daten-Management und Multi-scale Datenanalyse
Das e:KID-Projekt generiert ein großes Spektrum verschiedener Datentypen, darunter klinische Daten, Genexpressionsdaten, Zytokin-Daten, epigenetische Daten, Metabolomics-Daten sowie Daten aus HLA-Antikörpermessungen und Viruslastmessungen. Um eine umfassende Datenanalyse zu ermöglichen, müssen alle diese Datentypen in eine gemeinsame Ressource integriert werden. Um dieses Ziel zu erreichen, kann die MicroDiscovery GmbH auf lang etablierte Methoden und Erfahrungen zurückgreifen (BioMiner: Wegbereiter für personalisierte Medizin. (PMID: 26005322)). Im e:KID-Projekt erstellen und verwalten wir eine integrative Datenbank für alle im Konsortium generierten Daten. Die Datenbank wird regelmäßig aktualisiert und allen Projektpartnern zur Verfügung gestellt.
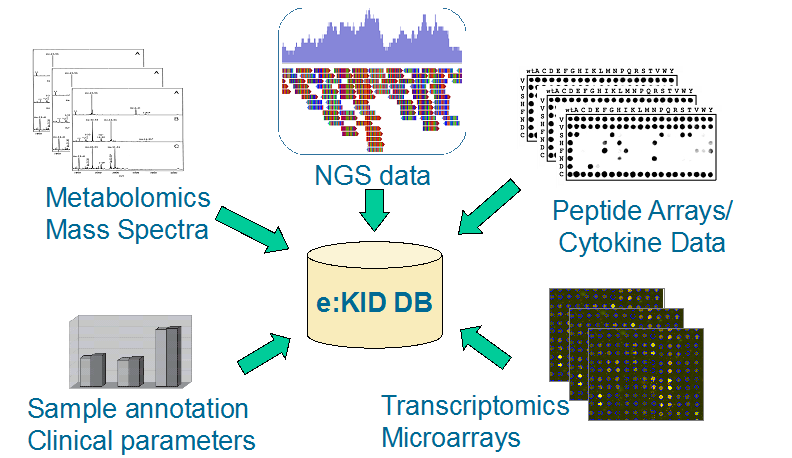
Integration of multiple data sources into the e:KID database
Neben der Datenverwaltung trägt MicroDiscovery zur Datenanalyse bei. Die im Projekt generierten Daten sind nicht nur Cross-Omics, sondern auch zeitaufgelöst, heterogen und hochdimensional. Um verborgene Verbindungen zwischen Multiskalenmarkern zu entdecken, werden multivariable Statistiken und Zeitreihenanalysen auf die Daten angewendet. Diese Analysen ermöglichen es, Biomarker zu identifizieren, die mit einem positiven Langzeitergebnis in Zusammenhang stehen, und helfen, personalisierte Behandlungen für Patienten zu entwickeln, die Nierentransplantationen benötigen.